Monolith or Microservices? Neither, Combine Both With Integrated Microservices
What we need is a hybrid solution that keeps the advantages of both architectures.
Motivation
Some projects are currently moving back from a Microservice architecture to a Monolith architecture (Segment, Istio, InVision, ...). Furthermore, greenfield projects ask themselves if they have to start with a Monolith or with a fleet of Microservices. The Microservice Architecture adds a lot of complexity that most of us can't easily manage, and Monoliths can't follow the growth of an organization.
Advantages of Monoliths
- Better availability (in-process inter-service communication)
- Debugging
- Testability
- Observability
- Cheaper to develop
- Simpler to deploy
Advantages of Microservices
- Simpler team partitioning
- Better team autonomy
- Faster maintenance
- Tailored scalability
- Faster release of new features
The goal of this article is to describe a Solution for an architecture that is both easy to grow and highly available, something between a Microservice and a Monolith.
Forces
According to the Reactive Manifesto :
We believe that a coherent approach to systems architecture is needed, and we believe that all necessary aspects are already recognised individually: we want systems that are Responsive, Resilient, Elastic and Message Driven. We call these Reactive Systems.
Systems built as Reactive Systems are more flexible, loosely-coupled and scalable. This makes them easier to develop and amenable to change. They are significantly more tolerant of failure and when failure does occur they meet it with elegance rather than disaster. Reactive Systems are highly responsive, giving users effective interactive feedback.
The mean to achieve these architecture characteristics is by using Messages for inter-component communication, well ... mostly, as we'll see later. So the main Non-Functional requirement here is Availability of the whole system (responsiveness), even in case of the crash of a component. It is achieved by making components & their interactions Redundant and Recoverable (elastic). In 8 Fallacies of Distributed Systems, we can read that the Network and remote communications are clearly the culprits. Remote access WILL fail, or worse, will be slow and, at the end, will freeze all resources. An answer to this issue is to design systems with this key principle : reducing remote access as often as possible.
So, the first force to design distributed systems is reducing remote calls. We can do this by making our APIs coarse-grained, using Event-carried State Transfer, or by using a Proxy (see later). Microservice Architecture produces distributed systems but Monolith Architecture produces integrated systems. So Monoliths win this first force : they are more resilient than Microservices to remote communications. Another trait when designing distributed systems is the coupling between components. This second force allows teams to work in parallel more easily and be autonomous from each other if components are loosely coupled. So Microservices win this second force : they are often more loosely coupled than Monoliths. Microservices are mainly an organizational Pattern, aligned with Conway's law. We need a way to reconcile these 2 opposite forces into a single design : a loosely coupled BUT integrated system, some kind of Modular Monolith.
Commands, Events & Queries
Messages may have 3 types : Queries, Commands and Events. The difference between them lies in their intent :
- Queries are requests for immediate information, without any side effect on data (read-only operation)
- Commands trigger something which should happen in the future and that often has side effect on data (read-write operation). A Command should be validated before executing it (format, structure, semantic, authorization on the endpoint or data scope). It may be an opposite operation so that we can undo the work of a previous Command. This is useful in the SAGA Pattern
- Events inform about something which has happened in the past, is immutable and already completed. They often mean the change that has occurred after a Command execution (Success or Error) and may carry some data or links to data
Synchronous versus Asynchronous
- A Synchronous operation is when a client invokes an operation on a server and waits for the result before doing another task
- An Asynchronous operation is when a client invokes an operation on a server and immediately execute another task without waiting for the result of the first one. If a response is asked, then another request is executed to push/pull the response as soon as it is available.
Commands, Events & Queries can be Synchronous or Asynchronous.
Point-to-Point versus Publish/Subscribe
These are 2 Messaging Patterns which indicate what consumer(s) will receive a message :
- In the Point-to-Point pattern, the message is sent from a Sender to only one Consumer, defined in advance
- In the Publish/Subscribe pattern, the message is sent from a Publisher to several Subscribers, all at once. Contrary to the Sender in the Point-to-Point Pattern, a Publisher does not know who will consume its messages
Commands, Events & Queries can be sent using both Patterns. Point-to-Point can be Synchronous or Asynchronous.
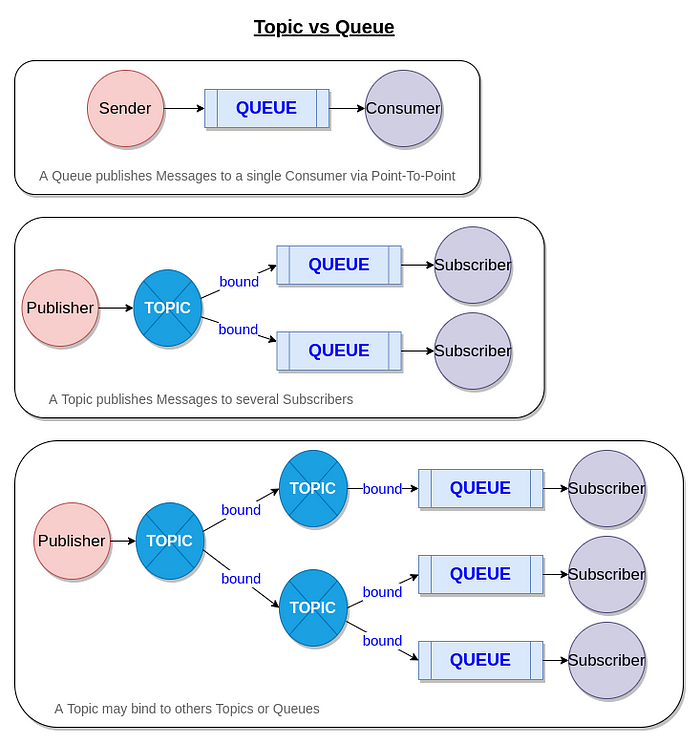
Topic versus Queue
A Topic & a Queue are placeholders where messages transit through a pipe. They are usually managed by a Broker and messages may be stored in-memory and/or on disk. Their retention time may vary depending on the configuration, and the Broker type.
- A Queue means a message goes to one and only one possible consumer
- A Topic send messages to all subscribers
In RabbitMQ, a Topic is an Exchange, and a Queue is a Queue. A Queue is bound to an Exchange. An Exchange may be bound to another Exchange also. In Kafka, a Topic is a Topic and a Queue is a Consumer Group.
Microservice Modularity
The first pillar of the Solution is to keep a Microservice architecture, due to its modularity and organizational efficiency. So, each component will have a single-purposed API as its only inbound public interface, and its own encapsulated data. What follows are patterns to mitigate the disadvantages of this architecture, mostly :
- the risk of unavailability (cascading slowness or errors)
- the difficulty to operate them easily at scale
Microservice Interactions
A Microservice may be seen as a cell in which there are Inbound and Outbound interactions : it may receive/send Commands, Queries or Events. Either Synchronously or Asynchronously. Either with the Point-to-Point or Publish/Subscribe pattern. So, we have to choose a combination of all these possibilities to reconcile the forces described above into a design that is highly available and easy to operate at scale. For both Inbound and Outbound interactions, the Solution consists of designing endpoints and remote access :
- Synchronously for Queries, because the true purpose of a Query is to request data immediately
- Asynchronously for Commands & Events, because it makes the whole system natively much more available (only the message broker has to be available when sending/receiving a message)
So we design that each Microservice has :
For Inbound Messages
- an API for Queries. It behaves as a Data Finder (blocking Request/Reply)
- a Topic for Commands & Events. The Microservice behaves as a Command Receiver & an Event Subscriber. This inbound Topic is bound to 2 internal Queues (one for Commands, another for Events)
For Outbound Messages
- another Topic for Events only. The Microservice behaves as an Event Publisher. These Events may be DDD Domain Events telling that some Business Aggregate has changed
- Outbound Queries & Commands will be sent directly (Point-to-Point) to the inbound API/Topic of a dependent Microservice

The second pillar of the Solution is this combination of interactions.
Proxy versus Backend
Commands have to be validated before being accepted. Furthermore, it may be necessary to return some identifiers (Request Id, Resource Id, Saga Id) so that the Command sender might correlate a future asynchronous response. As we designed that inbound Commands are asynchronous, we'll use the API-Queue-Worker pattern for separating the validation part (API) from the execution part (Worker) with a Queue between them.
- Firstly, the Command is received by an API Controller, the Microservice Proxy, and if its validation is successful, then it is published into an Inbound Topic for later processing, then it returns identifiers. If not validated, then an error is returned (code 4xx)
- Secondly, a Worker instance, the Microservice Backend, consumes the Command from the internal Command Queue, calls necessary dependencies and processes it. This Command Queue is bound to the previous Inbound Topic
Inbound Events are fully asynchronous, so they are NOT consumed by the Proxy, but instead consumed and handled by the Backend. On the contrary, inbound Queries will ALL be executed by the Proxy, not the Backend (except an Admin API perhaps).

Furthermore, the Proxy should NOT call any remote service except :
- the message Broker (to forward Inbound Commands)
- its Database (for Read-Only requests)
The Database & Broker are both its only Synchronous dependencies :
- So, some timeout, automatic retries, circuit breaker, logs & metrics collectors have to be set up for making these 2 interactions resilient and observable. This could be executed on the Proxy-side with a shared library or a sidecar
- Several Read-Only Database Replicas could be used by the Proxy in order to improve its availability with these 2 add-ons in front of the database : a Read-Only Replica Load Balancer & a DB Connection Pooler

You could embed both containers (Proxy & Backend) inside the same POD to serve read-only requests from the Read-Write Database. It could be useful when doing a version upgrade of the Read-Only Databases (unable to serve read-only requests from the Proxy).
The Backend may call any remote service in addition to calling its dependent Proxies, its Database & the Message Broker. This would include ERP, SAAS and Legacy applications. The Proxy is the only public interface of the Microservice, indeed you can't access the Backend, neither Synchronously nor Asynchronously. The Backend should use the Outbox Table Pattern to update its data and send messages as a single unit of work (i.e., either rollback or commit).

The third pillar of the Solution is this Proxy/Backend split.
Proxies as Ambassadors
So far, we have chosen to design a Microservice with 2 parts :
- a Proxy, where
- Commands are validated and forwarded (if validation is successful)
- Read-Only Queries are executed - a Backend, where
- Commands are processed
- Events are subscribed and published
- Dependent APIs are called (via other Proxies)
These 2 parts may be provided as 2 different images, tailored for their respective usage. They would be built from the same source code repository, via a single CI/CD pipeline. So, the Proxy image should usually be lightweight : API Controllers, Database reading and Command publishing. The main idea here is to deploy the Backend container with ALL its dependent Microservice (Proxies) as Ambassador containers (sidecars). So, a Backend POD would contain :
- a Backend main container
- several Proxy Ambassador containers (dependent Microservices)
All interactions between these containers will be done synchronously on the same localhost via the API of each Proxy. No Kubernetes Service is needed to access them, just dedicated ports for each Proxy. We gain a lot on latency, security and availability.
For example, a Backend-For-Frontend POD would only embed the Proxy Ambassadors that it needs, not their Backends. Of course, we still may use multiple replicas of this POD to achieve Resilience and High Availability. Like with any Proxy container, the Backend container synchronously calls the Database (read-write) & the message Broker. Both of these infrastructure components should be made Highly Available.


The fourth and last pillar of the Solution is the use of the Ambassador Pattern for the Deployment of Proxies.
Proxy Deployment Variations
We can deploy all dependent Proxies of a Microservice Backend in different ways :
- as Ambassador containers (same POD), the recommended way, because inter-service communications are done on localhost
- as Libraries (same process)
- or as PODs deployed in the same Node/Host as the Backend POD using Topology Aware Hints or Service Internal Traffic Policy
It is even possible to have a mix of this 3 ways. It depends on the nature of the dependency (support service, inner-sourced, core functionality, generic service), and its frequency of change. We can also have different deployments for different environment (DEV : In-Process, UAT: same Node, PROD: Ambassadors). You don't have to change the code whatever the deployment model!!!

Proxy Version Upgrade
As long as a Microservice DB Schema is backward compatible for reading, there is no need to replace the Proxy container. Anyway, you could implement Automatic Proxy Container Replacement by providing a Liveness Probe for each Proxy container. The Probe would check the current version of its Schema in database, and would return non-zero (failure) if any upgrade occurred. Kubernetes would then automatically restart the Proxy container by ALWAYS getting the last Image.
Native Observability
We can duplicate (fanout) all Events/Commands into ElasticSearch in order to monitor the Business Flow of messages without adding any new line of code. This can be done :
- In RabbitMQ, by binding exchanges (some providing the messages, and another exchange to be consumed by ElasticSearch)
- In Kafka, by using a KsqlDB script merging all messages into an ElasticSearch Topic
A Tracing Identifier (ex: Flow ID) has to be added into each message so that we can group messages (Commands & Events) by each Business Flow. A Business Flow is all messages fired from a single Business request.

Conclusion
We detailed a Solution that allows to develop Microservices (still) in an independent way but by making them less fragile to network communications, and issues from distributed systems. We mainly used asynchronous updates (Commands), and the collocation on the same POD/Node of a Backend with all its Proxied dependencies. This makes inter-service communication mostly on the localhost, except when accessing legacy applications, SAAS & infrastructure (Database & Broker).
This kind of architecture that favors global availability could be named the Ambassador Architecture, isn't it?
